




















Blogs
From Chaos to Clarity: Harmonizing Data
As pharmaceutical and diagnostics companies, and research organizations increasingly tap into a myriad of data sources—from clinical trials to patient records and laboratory tests to genetic tests—the ability to merge these diverse data streams into a unified, actionable format is more crucial than ever. Integrating such heterogeneous data poses a significant challenge due to the extensive variability in data quality, formatting, standardization, and organization. However, despite these challenges, harmonizing data is crucial from a strategic standpoint as it has the potential to drive innovation, enhance patient outcomes, and accelerate drug development in a time-saving and cost-effective manner.
Unharmonized data can have several negative implications. It can lead to inefficiencies in data management which can result in delays in decision-making and analysis. For example, in clinical trials, data from different sites or sources that are not harmonized can result in delays in drug development and hinder the identification of effective treatments.
Additionally, data discrepancies due to a lack of harmonization can introduce errors and inaccuracies, compromising data reliability. Furthermore, incomplete, inconsistent, or duplicated data can hinder insights and pattern discovery, limiting the ability to draw meaningful conclusions from the data.
Thus, harmonizing data is crucial not only because it enables a seamless integration of information from diverse sources but also enhances the reliability of data-driven decisions.
Strategies for Achieving Data Harmony
In the context of pharmaceutical diagnostics and research, one of the major challenges with data harmonization lies in managing the sheer volume and variety of data. For example, a single clinical trial can generate several terabytes of data as it involves collecting data from participants, including medical records, lab results, imaging data (such as MRI or CT scans), and electronic health records (EHRs).
Genomics studies, especially precision medicine trials involving NGS and data analysis, can produce large amounts of data [2]. In fact, a typical phase 3 trial can employ up to 10 data sources leading to the generation of an average of 3.6 million data points, marking a three-fold increase compared to data volumes reported a decade ago [1].
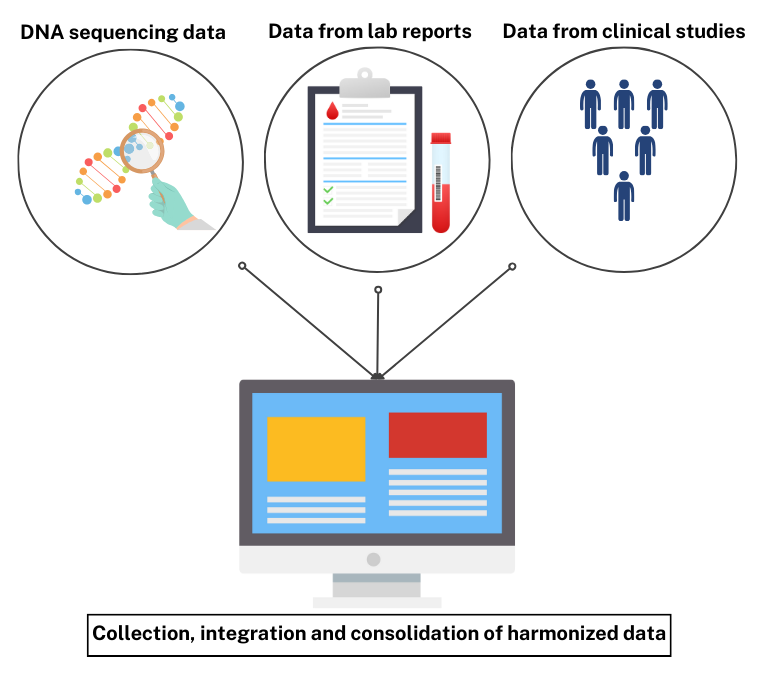
To address these challenges, a streamlined process- from the collection of data to the integration and consolidation of the harmonized datasets into a database- can be put into place to provide a smooth and effective solution.
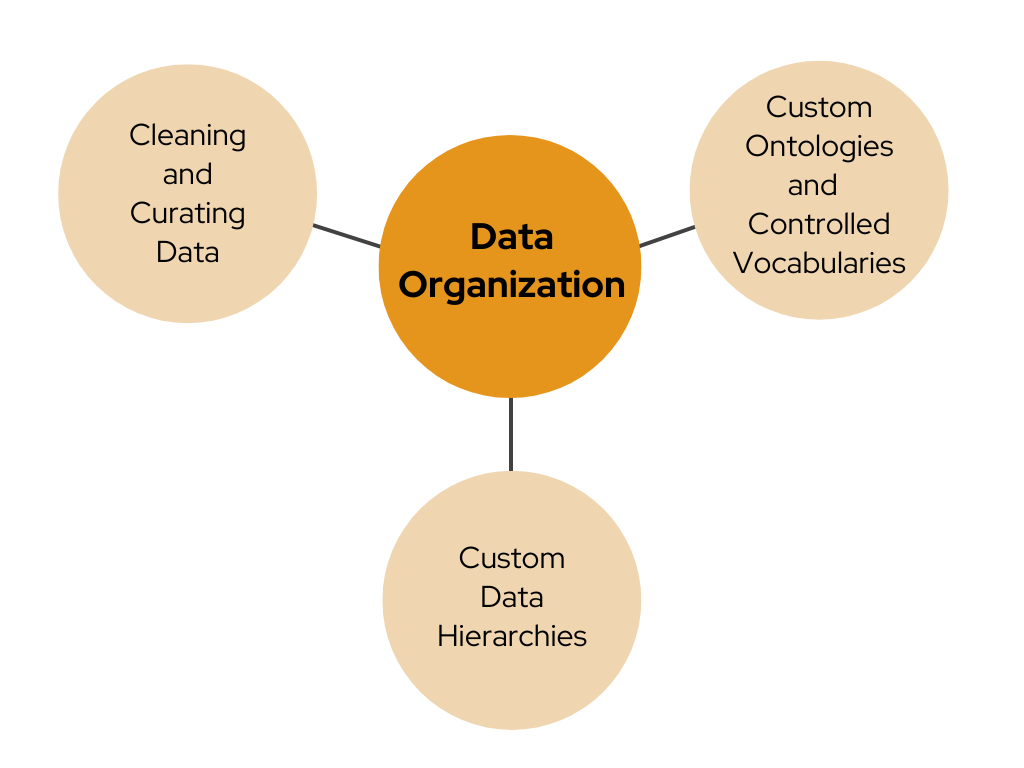
Strand's team, comprising experts in curation, bioinformatics and data engineering, possesses extensive expertise in data cleaning, integration, and harmonization and offers data organization solutions including:
- Cleaning and Curating Data: Ensuring the accuracy, consistency, and relevance of data sets
- Creating Custom Ontologies and Controlled Vocabularies: Developing specialized frameworks for data categorization and terminology standardization
- Creating Custom Data Hierarchies: Establishing structured data classifications to enhance data analysis and retrieval
Strand offers support to pharmaceutical, biotech, and diagnostics companies, assisting them in effectively organizing data for various research applications.
A recent example of this is our collaboration with a leading pharmaceutical company in the US that required data cleanup and organization of their biomedical datasets. To meet their requirements, we developed a streamlined five-step process from data collection to uploading harmonized and consolidated datasets into the client’s database, thus providing a unified platform for seamless analysis across diverse data sources and ensuring accessibility for researchers throughout the company.
Visit our solutions page for more information.
To sum it up, data harmonization paves the way for a more efficient and insightful data landscape, driving progress and growth in an increasingly data-driven world.
For a more in-depth exploration of how we helped a big pharmaceutical company with data harmonization, read this case study!
You can find the rest of the blog series below:
- Part 2: What’s in a Term?
- Part 3: Resolving Ontology Inconsistencies: Insights from Strand's Approach
- Part 4: Harnessing the Power of Harmonized Data: Strand’s Approach
References:
- Data First: Building a Foundation for Digital and Decentralized Clinical Trials
- Herland, M., Khoshgoftaar, T.M. & Wald, R. A review of data mining using big data in health informatics. Journal of Big Data 1, 2 (2014).
Let's Connect
Let's Connect

download the case study.