



















Blogs
3x Faster Metadata Curation Using LLM and RAG in Strand’s scRNA Portal
Metadata curation is crucial for managing and utilizing biological datasets, particularly in areas like single-cell RNA sequencing (scRNA-seq). This process involves organizing and describing datasets, enabling researchers to effectively understand and utilize the information. In scRNA-seq, where datasets are large and complex, precise metadata is vital. scRNA-seq datasets often have missing or incomplete information for disease phenotypes, treatment conditions, sequencing instruments, and other key attributes. Properly curated metadata not only helps in filling in these gaps and accurately organizing these datasets but also in identifying significant biological patterns and insights by integrating data across studies. This ultimately improves research reliability and data usability across studies, aiding in scientific discoveries such as potential biomarker identification and therapeutic target development.
Why Automate Metadata Curation?
Traditionally, metadata curation has been a labor-intensive task, consuming significant time and often leading to inconsistencies. Automation addresses these challenges by:
- Dramatically reducing turnaround times—from weeks to days—allowing for quicker transitions from data gathering to analysis.
- Enhancing consistency, accuracy, and reliability across datasets, which is essential for reproducible results.
- Enabling scalable handling of large datasets without compromising detail or accuracy.
By automating metadata curation, researchers can focus more on interpreting biological insights rather than on manual standardization.
What is Retrieval Augmented Generation (RAG)?
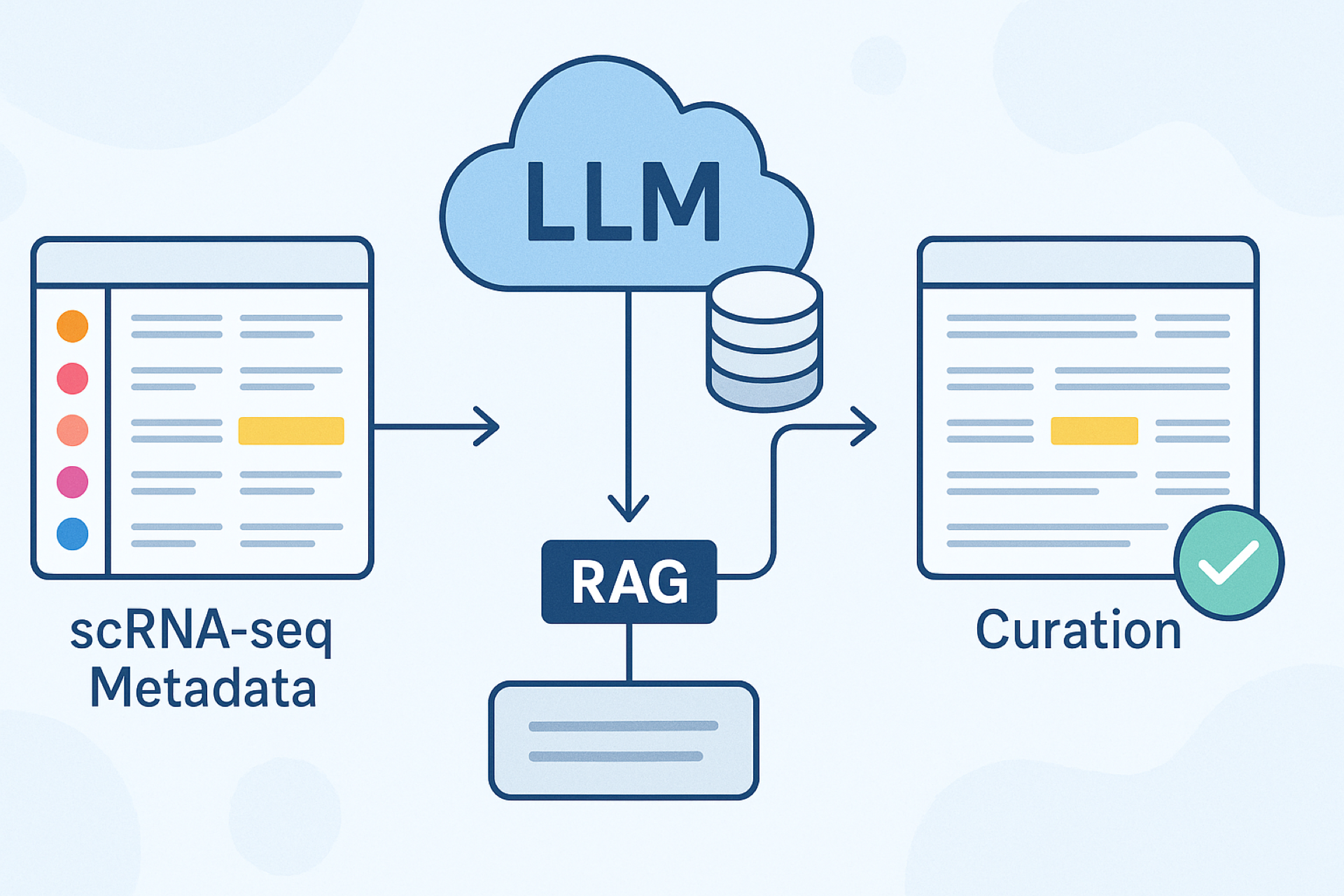
Retrieval Augmented Generation (RAG) is an innovative technique that boosts the capabilities of Large Language Models (LLMs) by integrating relevant external information during the metadata normalization process.
In Strand’s scRNA Portal, RAG works by retrieving contextually relevant terms from specialized biomedical knowledge bases, enabling the LLM to accurately refine and standardize metadata. This integration has demonstrated a three-fold reduction in token usage and computational costs compared to traditional prompt-based methods.
The pipeline was rigorously tested against manually curated ground truth data in Strand’s scRNA Portal, leading to faster performance and significantly improved accuracy—reaching up to 95.38% in normalizing biomedical terms, particularly those related to Inflammatory Bowel Diseases (IBD).
Balancing Automation with Manual Expertise
Despite the gains from automation, some challenges remain. While LLM-based normalization is highly effective, precision issues occasionally necessitate manual verification. Additionally, not all metadata fields are suited for full automation. A hybrid approach—combining traditional methods with RAG-enhanced LLMs—offers a scalable and high-quality solution for metadata ingestion.
Strand’s scRNA Portal brings these capabilities together, enabling researchers to work faster and more confidently with curated data. Equipped with an automated metadata ingestion pipeline, the portal hosts meticulously curated datasets that are both accessible and easy to navigate. To learn more about the portal features, including its curation levels, filters, and search functionality, read our brochure.
Key benefits include:
- Metadata Automation: Rapid and accurate normalization of biomedical terms using a sophisticated pipeline combining GPT-4o and RAG.
- High Accuracy: Biomedical text-specific embeddings significantly improve accuracy compared to natural language embeddings.
- Cost and Time Efficiency: Approximately 3x reduction in turnaround time and computational resources compared to purely manual curation and traditional prompt-based methods.

Strand’s automated metadata ingestion pipeline, powered by advanced RAG and LLM technologies, provides a robust, scalable, and accurate solution for scRNA-seq metadata curation. By minimizing manual effort and associated costs, the portal enables faster access to expertly curated data—supporting quicker insights and more scalable research in complex disease areas such as IBD and Alzheimer's disease (AD).
For more information please refer to our poster and brochure. To explore Strand’s scRNA Portal, please click here.
AI/ML Series
25 Jun 2026
Agentic AI for Scalable Exploration, Curation, and Analysis of Biomedical Data

Precision Medicine
19 Jan 2026
TileDB and Strand Life Sciences: Solving Genomic Data Bottlenecks with Unified Data Architecture and AI Analytics
Precision Medicine
28 Nov 2024
AI or Manual Curation: The Path Forward
Let's Connect
Let's Connect

download the case study.