




















Blogs
Maximizing Data Power: The Role of Data Pooling in Pharma Research
In a landscape where information is hailed as the currency of power, the pivotal role of data stands indisputable. Fueled by the capabilities of Artificial Intelligence (AI) and Machine Learning (ML), organizations find themselves in a relentless race to secure access to data and build capabilities to leverage data. Bioinformatics and genomic data are essential for advancing precision medicine, allowing medical interventions based on individual genetic profiles. The combination of data and advanced technologies is now crucial for biotechnology companies shaping their strategies and setting them apart in the competitive landscape.
Simply put, 'Data Pooling' means gathering data from different places. When applied to the pharmaceutical industry, this process becomes highly impactful. Having a wealth of data enables the ability to make informed decisions and gain insights. Pfizer has used AI and data repositories to develop new drugs like PAXLOVID, an oral COVID-19 treatment approved in 2022, in a short span of four months [1]. Pharma Research and Development is heavily backed on data—information about molecules, results from experiments, details from patients, and findings from clinical trials—making the process of data pooling a powerhouse for driving advancements.
At every turn of the process, the careful management of relevant data holds immense importance. Data pooling, where information from diverse populations with varying sizes and demographics is brought together to identify drug targets, serves as a gateway to precision medicine. This approach allows researchers to explore how drugs impact each person uniquely and how we can improve medications to create more effective treatments and enhance clinical outcomes.
Another impactful capability that data pooling unlocks is the ability to foster collaboration among scientists and researchers, regardless of their geographical locations. This approach promotes a unified, single-lab methodology, facilitating the sharing of insights, ideas, methods, and data as researchers collaborate towards a shared objective. In the intersection of data and pharmaceutical research, the combined synergy arising from diverse datasets is charting the course for a new era of groundbreaking discoveries.
Data pooling and integration propel biological discoveries, yet harmonization poses a challenge. Achieving synergy among diverse datasets involves addressing format variations.
At Strand, our teams specialize in organizing data, ensuring harmonization. The process includes compiling data into a hierarchical structure, curating metadata, and standardizing terminologies using ontologies and controlled vocabularies/dictionaries of terms, enabling researchers to concentrate on core objectives. If you're interested in gaining a deeper understanding of our expertise in data harmonization, you can explore the details in this comprehensive case study.
FDA Rule on Lab Developed Tests (LDTs)
10 Sep 2024
Understanding Compliance Tiers for Laboratory Developed Tests (LDTs)

Precision Medicine
03 Apr 2023
Why is Genomics Key to the Future of Preventive Healthcare?
Precision Medicine
23 Jun 2025
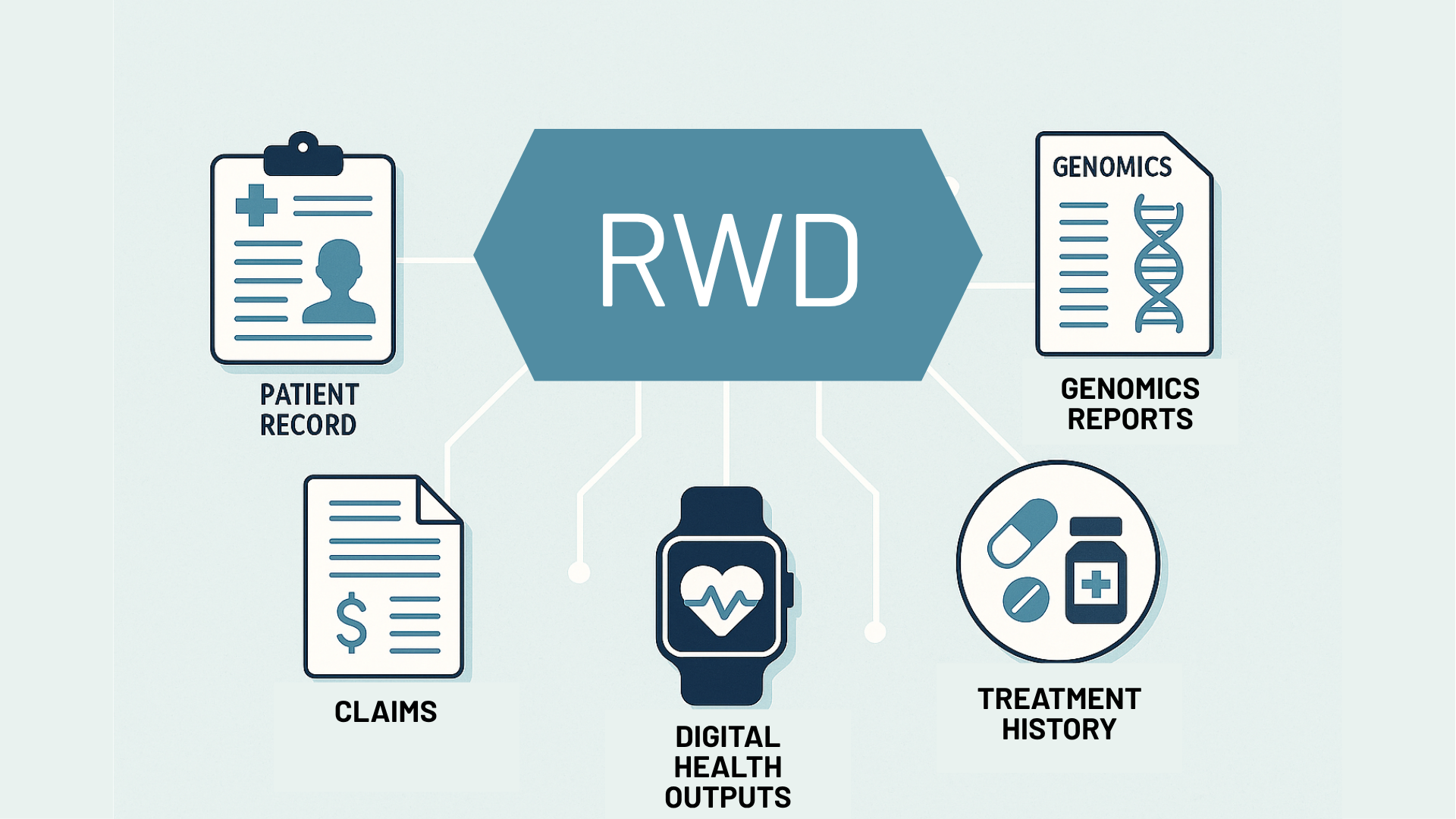
From Raw Data to Real-World Insights Through Strand’s Data Harmonization and Curation Capabilities
Let's Connect
Let's Connect

download the case study.