



Blogs
Bracing for the Petabyte Era in Genomics
A quick look at the latest genome sequencing costs tracked by the National Human Genome Research Institute (NHGRI) shows that the cost of DNA sequencing has plummeted between 2001 and 2022.
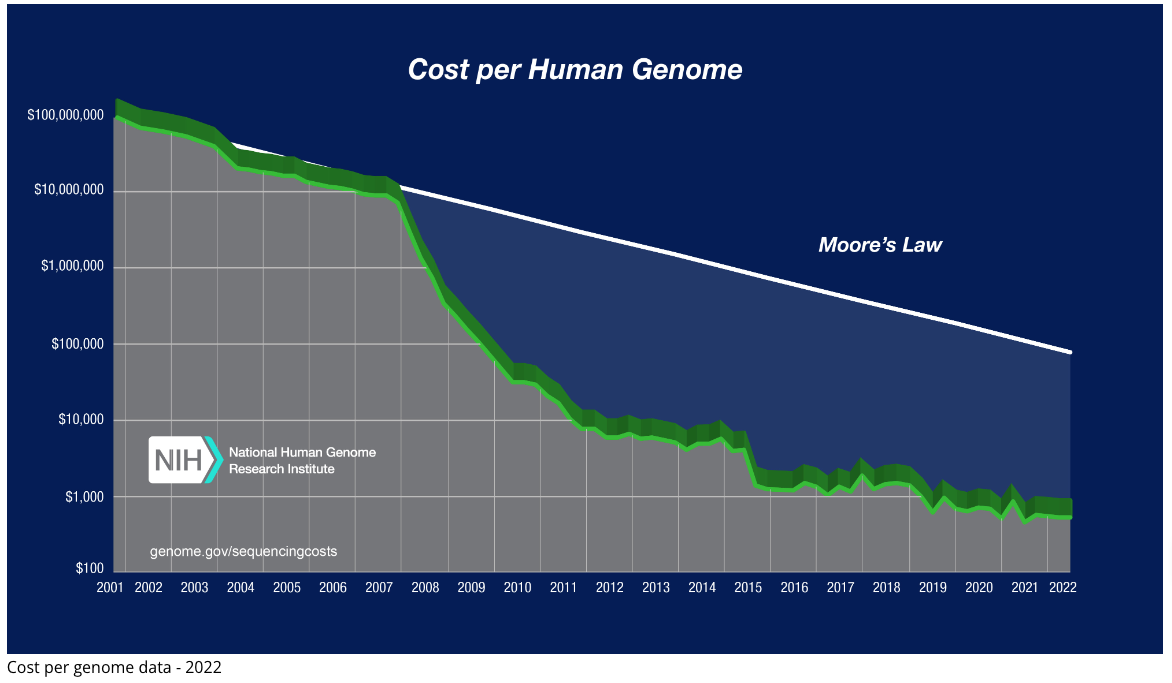
Further, Illumina has recently claimed that whole genome sequencing on the NovaSeqX can be completed for as little as $200.
While this consistent downward trend offers great promise for the genomics industry, it has uncovered a new challenge: this vast amount of data needs to be processed and stored in cost-effective ways before interpretation can begin.
Moreover, given that sequencing projects (especially those pertaining to population health and clinical trials) increasingly include large sample sizes, the data generated is often in the order of terabytes. These volumes are slowly exceeding the capacity of on-premise servers, necessitating the use of robust and scalable cloud solutions.
For bioinformatics labs aiming to optimize turnaround time (TAT) by migrating to the cloud, popular options include Amazon AWS, Microsoft Azure and Google Cloud Platform.
However, the problem isn’t completely resolved until the infrastructure is set up to optimize performance and minimize storage costs.
On a related note, I was recently at a talk at Bio-IT World 2024, where Grigoriy Sterin, Senior Principal Engineer from Tessera Therapeutics, a gene editing company, elaborated on how they built their data platform by continuously overcoming challenges in their cloud infrastructure.
Grigoriy emphasized the importance of the following measures for scaling up while moving away from manual and cumbersome setups -
- Storing results in a shareable way
- Tracking and automating workflows
- Using workflow engines that support parallelization
Considering these nuances are indeed effective ways to optimise cloud storage.
Echoing Sterin’s insights on overcoming cloud infrastructure hurdles, I’d like to highlight our poster at Bio-IT - Cloud Storage and Data Management Strategy for NovaSeq X+ Data - where we addressed scaling issues for our in-house genomics data using cloud storage.
This poster outlines our operations team's strategy for optimizing the storage and processing of NovaSeq X Plus (NSX+) data, aimed at efficiently managing more than 16 petabytes of data over the next decade.
In essence, the NSX+ generates 1.5 TB of data per run using the 10B flow cell.
Our data operations team - Srikant Sridharan, Aman Saxena, Priyanshu Agarwal - has developed a streamlined pipeline, incurring AWS costs of $300/run to process 100 samples. The total AWS cost includes compute and transfer at $220 and $80/run, respectively.
We streamlined this pipeline by adopting a few strategies -
- Centralizing data processing
- Eliminating S3 dependency and adopting an Amazon EC2 instance for computing and temporary storage
- Utilizing Azure for long-term storage

Our optimized data flow architecture yields a cost reduction of $650/run, saving 60% on cloud expenses.
You can download a PDF version of this poster from our website!
We'd be eager to discuss any challenges you may be facing with managing and storing your NGS data on the cloud.
Feel free to get in touch with our Business Development team - Radhakrishna Bettadapura, Jaya Singh, PhD Ernie Hobbs for more details!

Precision Medicine
06 Dec 2024
Strand’s Automated Variant Verification System Cuts Down Efforts by 80%

Precision Medicine
29 Apr 2025
How CytoRX AI Optimizes scRNA Analysis for Increased Efficiency

Precision Medicine
30 Jun 2025
Strand’s Bioinformatics Expertise Enables Liquid Biopsy Assay Development for NSCLC with 70% Cost Reduction and 2–5% VAF Sensitivity
Let's Connect
Let's Connect

download the case study.