




















Blogs
Anagrams as Primes
Two strings are anagrams of each other if one of them can be rearranged to spell the other. The best anagrams conserve not just their letters but also, mysteriously, a hidden meaning. So, for e.g: "Internet Anagram Server" is "I, rearrangement servant." or "Animosity" "Is no amity."
Problem #49 on LeetCode’s list of programming interview questions is to group all the anagrams in an input set of strings together. For e.g., if the input text is “listen”, “scramble”, and “silent”, the output groups “listen” and “silent” together because they’re anagrams, and “scramble” is ungrouped. Each word can be 100 letters long, and there can be as many as 10,000 words input. The goal of your program is to be as fast as possible while of course discovering, and grouping, sets of anagrams in the input.
A basic solution is to convert each string to its sorted representation, i.e., just the alphabetical ordering of its letters. For e.g., “silent” is “eilnst”, and so is “listen”. Words are anagrams of each other if their sorted representations are the same. So, in one pass, all words in the input list are converted to their sorted representations, and in a second pass, each word in the list is compared to its successors that are yet to be “discovered” as anagrams by comparing the respective sorted representations. If the sorted representations match, then the word is discovered and removed from the set of possible anagram candidates. The process is repeated until there are no further anagram candidates or the list runs out.
The issue with this approach is that it’s slow. In the first pass, sorting M strings of length N is O (MxN log N). In the second pass, the nested loop is O(M^2), with each inner nest taking O(N)comparisons.
To improve on this, we can use prime numbers. Say the first 26 primes each respectively represent the 26 letters, so a → 2, b→3, c → 5… z→101. Then multiplying the primes for each letter in a word will give you an anagram-proof representation. So “silent” = 67x23x37x11x43x71 = 1914801911, as is “listen”. Computing, and then comparing, the prime number representations in the first algorithm rather than the sorted representations should give us a decent speedup, because it's faster to compare numbers than strings. And indeed it does, a ten-fold improvement over using sorted strings.
When it works.There are two issues. One, for even 20-25 letter words, there are too many multiplications to store even in the largest data type, a 64-bit long long, and so there’s an overflow. Second, the nested loop is still inefficient. Despite our 10x speedup we remain in the bottom 5 percent. LOL.
The overflow issue is solved by remainders. After each multiplication we compute the remainder with respect to a large prime number p. So silent = (((67x23)%p)*37%p…). Picking p= 1e9 + 9 keeps all multiplications below the maximum representable 64 bit number.
The nested loop can be removed by using the prime representation (with the remainder trick) as a key in a hash table. Each value in the hash table is just the vector of strings in the input list that contains all anagrams for that key. At the beginning, this hash table is empty, and each time a new string in the list is encountered, its representation is computed and looked up in the hash table. If the entry already exists, then the string is added to the vector corresponding to the key; if not, a new vector is created. With these improvements, the algorithm gets a further 10x buff, and our execution time now beats 95% of all submissions. (Further improvements seem to be quirks of using the right type of C++ hashmap, for e.g., and probably not super relevant.)
The prime number multiplication idea is actually a reinvention of a very old “wheel”, a hash function. A hash function is a function that #1. maps its input to a unique representation and #2 is tough or nearly impossible to reverse unless the function is known. A standard hash function will yield different representations for “silent” and “listen”. For this problem, the additional idea is that you need a hash that treats anagrams the same, but gets you different hashes for non anagrams.
Philosophically, it makes sense that anagrams are prime number multiplications. Perhaps, stretching the analogy, what we see when we see a pair of anagrams is really that extremely large number, reachable only via a single multiplicative path, and apprehended through the words themselves, whose shared meaning is both strange and fitting at the same time.

Precision Medicine
03 Jan 2025
Comprehensive Genomic Profiling Reveals Disruptions in Key Cancer Pathways from Over 2,000 In-House Samples

Precision Medicine
17 Nov 2025
How Strand is Connecting the Dots Across Individual Clinical Journeys
Precision Medicine
30 Apr 2025
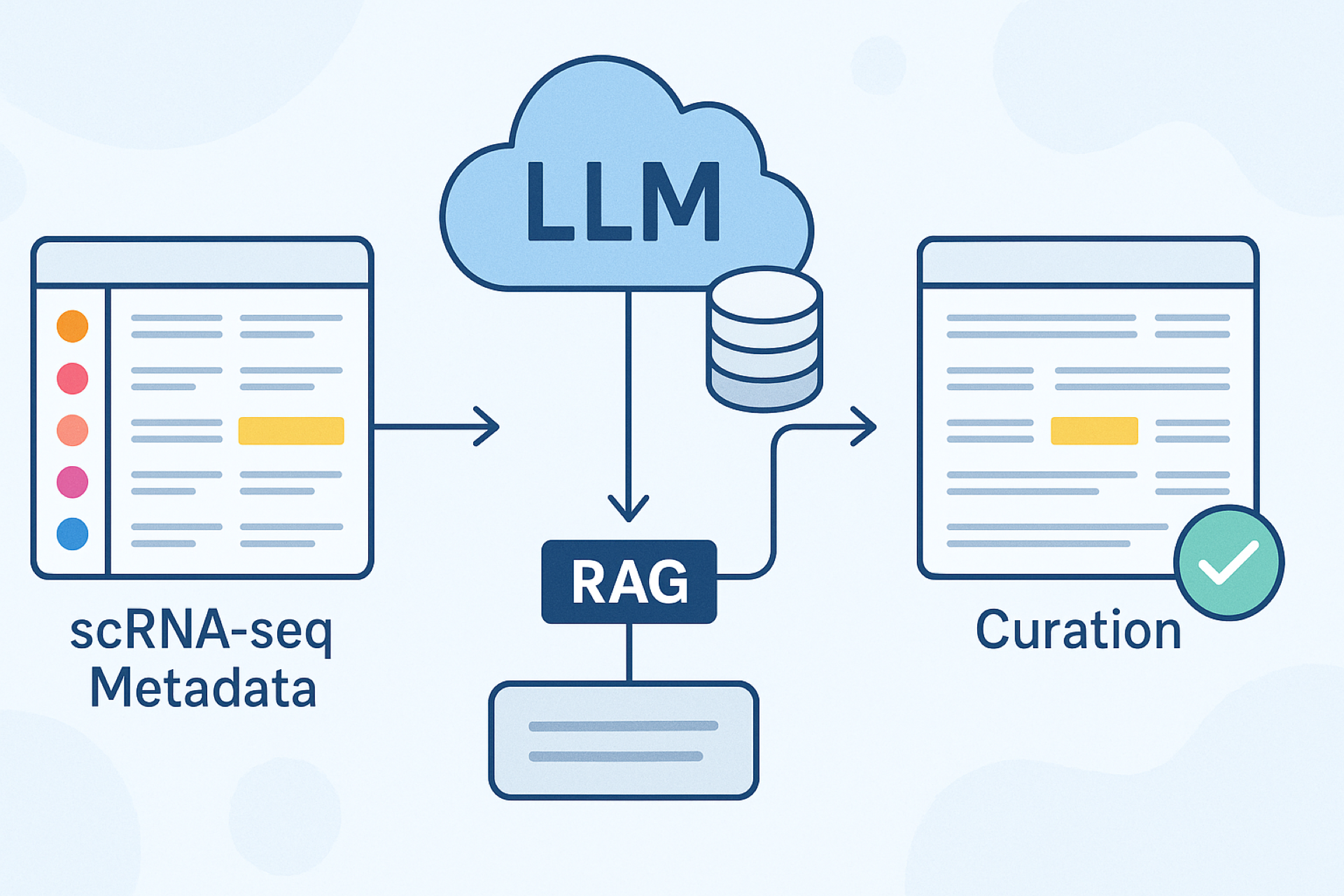
3x Faster Metadata Curation Using LLM and RAG in Strand’s scRNA Portal
Let's Connect
Let's Connect

download the case study.