



















Blogs
Agentic AI for Scalable Exploration, Curation, and Analysis of Biomedical Data
Biomedical research teams increasingly work with large, heterogeneous datasets that span public repositories, curated disease databases, sequencing studies, and internal research programs. While data availability has expanded rapidly, extracting meaningful insights remains challenging due to the scale, complexity, and multi-dimensional nature of modern biomedical datasets. Data exploration often relies on manual querying, scripting, metadata harmonization, cohort assembly, and exploratory analysis, making the process slow and resource intensive.
Identifying consistent patterns across large datasets is difficult to scale through manual review alone, particularly when data spans diverse formats such as numerical measurements, categorical variables, and unstructured text. As a result, researchers frequently require specialized programming skills to navigate and analyze data effectively, creating barriers to exploration and slowing the pace of discovery.
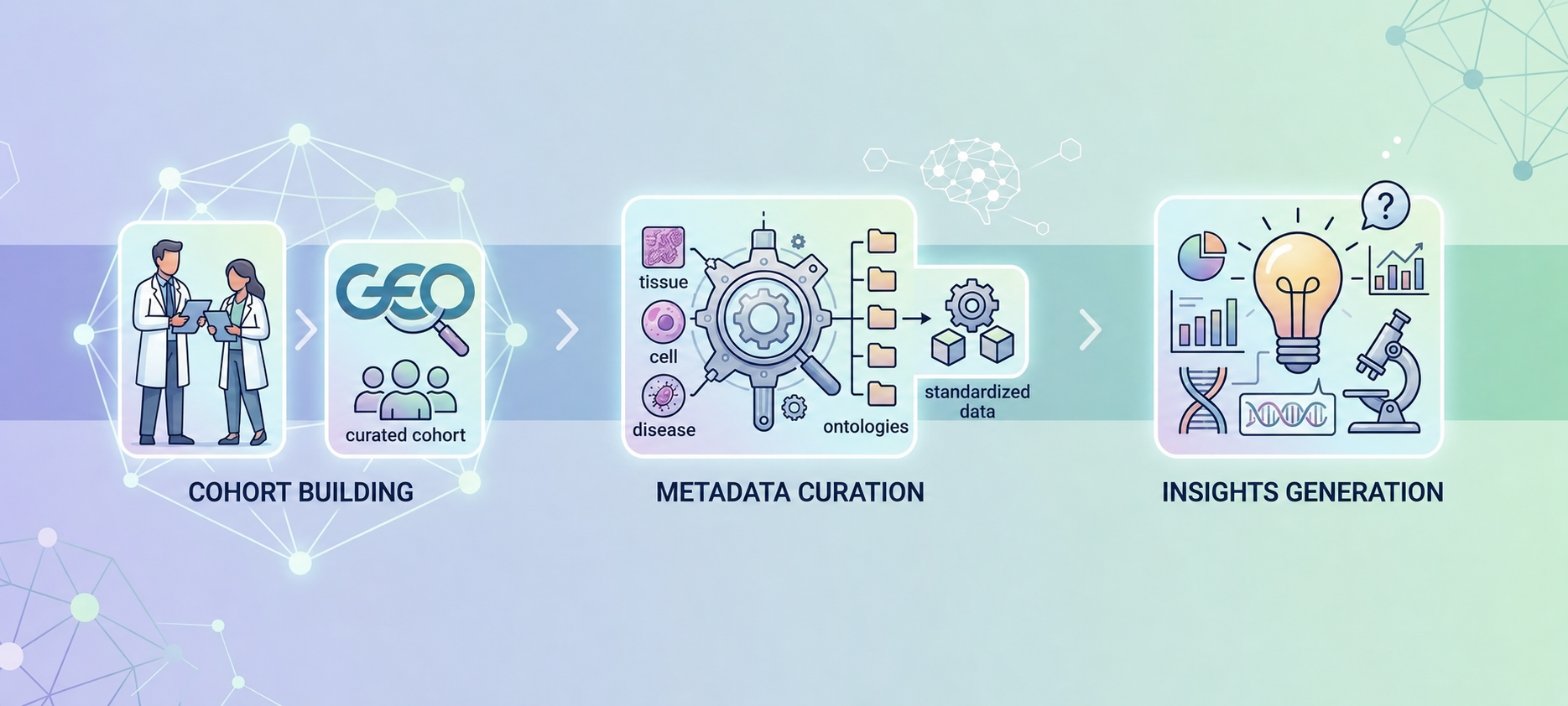
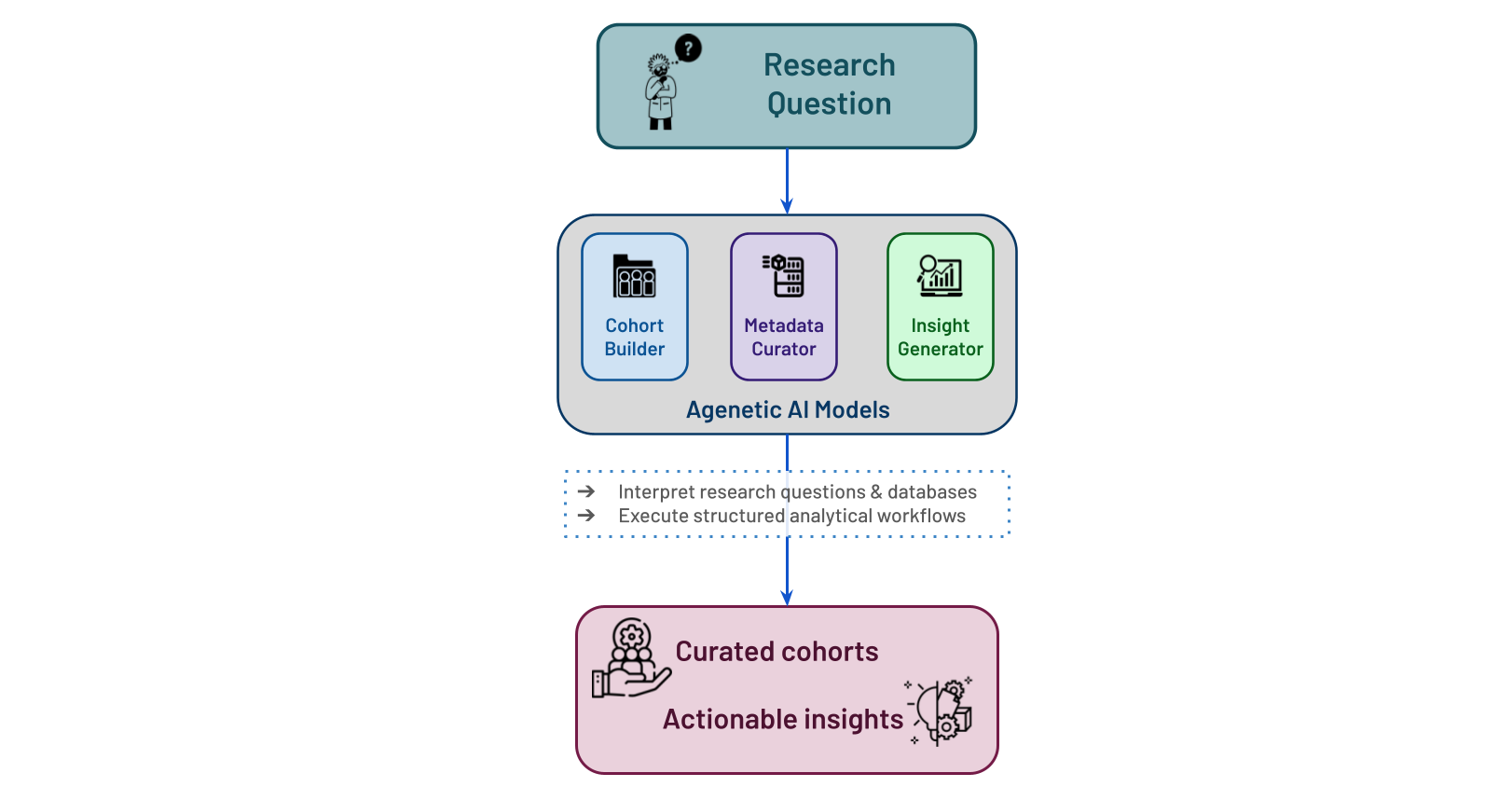
To address these challenges, Strand has developed a set of agentic AI models that support dataset discovery, metadata curation, and biological insight generation. Rather than functioning as a single chatbot, the platform uses specialized agents that interpret research questions, execute structured analytical workflows, and return traceable, database-grounded outputs. Together, these models help researchers move more efficiently from research questions to curated cohorts and actionable insights.
Agentic Cohort Building
Identifying relevant datasets is often one of the most time-consuming steps in exploratory research. Public repositories such as GEO contain vast amounts of information, but translating a biological question into precise search criteria can require multiple iterations and extensive manual review.
The cohort-building agent addresses this problem by converting natural-language research requests into repository-specific search queries. The system parses user constraints, generates executable search logic, validates returned results, and ranks cohorts based on relevance and quality. This allows researchers to move directly from a biological objective to a curated set of candidate studies.
Accelerated Cohort Identification at Scale
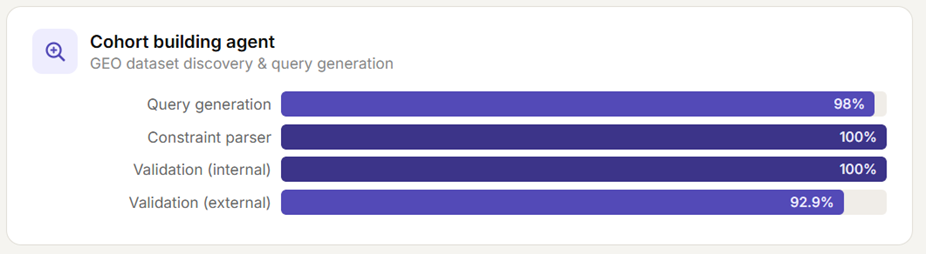
In internal evaluations, the structured query generation framework achieved 98% accuracy across 45 benchmark query pairs, while the query constraint parser achieved 100% accuracy. The result validation framework delivered precision scores of 100% on internal evaluation and 92.9% on larger external evaluations involving approximately 250 GEO study IDs. Average end-to-end execution time was 76.3 seconds per query, reducing dataset discovery timelines from hours or days to minutes.
The impact extends beyond speed. By automating the translation of scientific intent into structured search workflows, the model improves cohort quality while reducing the burden of manual dataset review.
Automated Metadata Curator
Even after relevant datasets have been identified, researchers often encounter inconsistent metadata, varying terminologies, and incomplete annotations. These inconsistencies make it difficult to compare studies, build large cohorts, or perform downstream analyses across multiple sources.
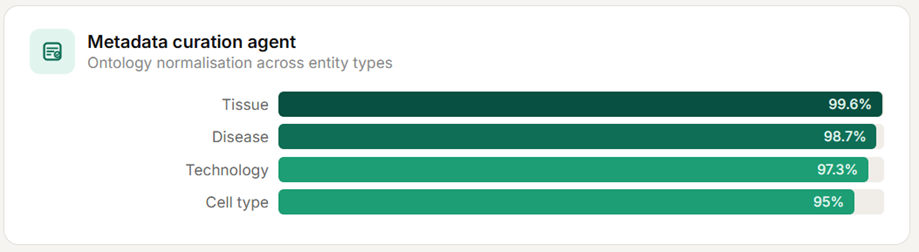
The metadata curation agent uses entity recognition and retrieval augmented generation to normalize experimental metadata to entity-specific ontologies such as DOID for disease terms. Terms extracted from raw metadata are mapped to standardized ontologies, assigned quality scores which can help users decide if the tool is appropriate to use in that instance, based on the quality of the recognition and normalisation process, and incorporated into a structured repository that can be queried consistently across studies.
Accurate and Efficient Curation
The model demonstrated high accuracy of normalization for disease (98.7%), tissue (99.6%), technology (97.3%), and cell type (95%). Across ~2500 samples from 144 studies, metadata normalization required approximately 90 seconds per study and reduced manual curation effort by an estimated 30–40%.
Case Study:
Need and Challenge: Automated ontology harmonization of disparate single-cell and clinical datasets that have no standardized metadata, missing fields, and may require normalisation, to create a unified database with a defined vocabulary for each field to enable searchability and curation at scale.
Solution: A tool which extracts entities from the raw metadata, applies RAG to the extracted phrases for normalisation and provides confidence scores based on the output of intermediate steps.
Impact: We were able to achieve >95% accuracy for the automated normalisation, with a 10X reduction in turn around time (TAT) as compared to manual curation, a 3X reduction in LLM token cost through the usage of RAG, and over 98% accuracy across 8 entity types. 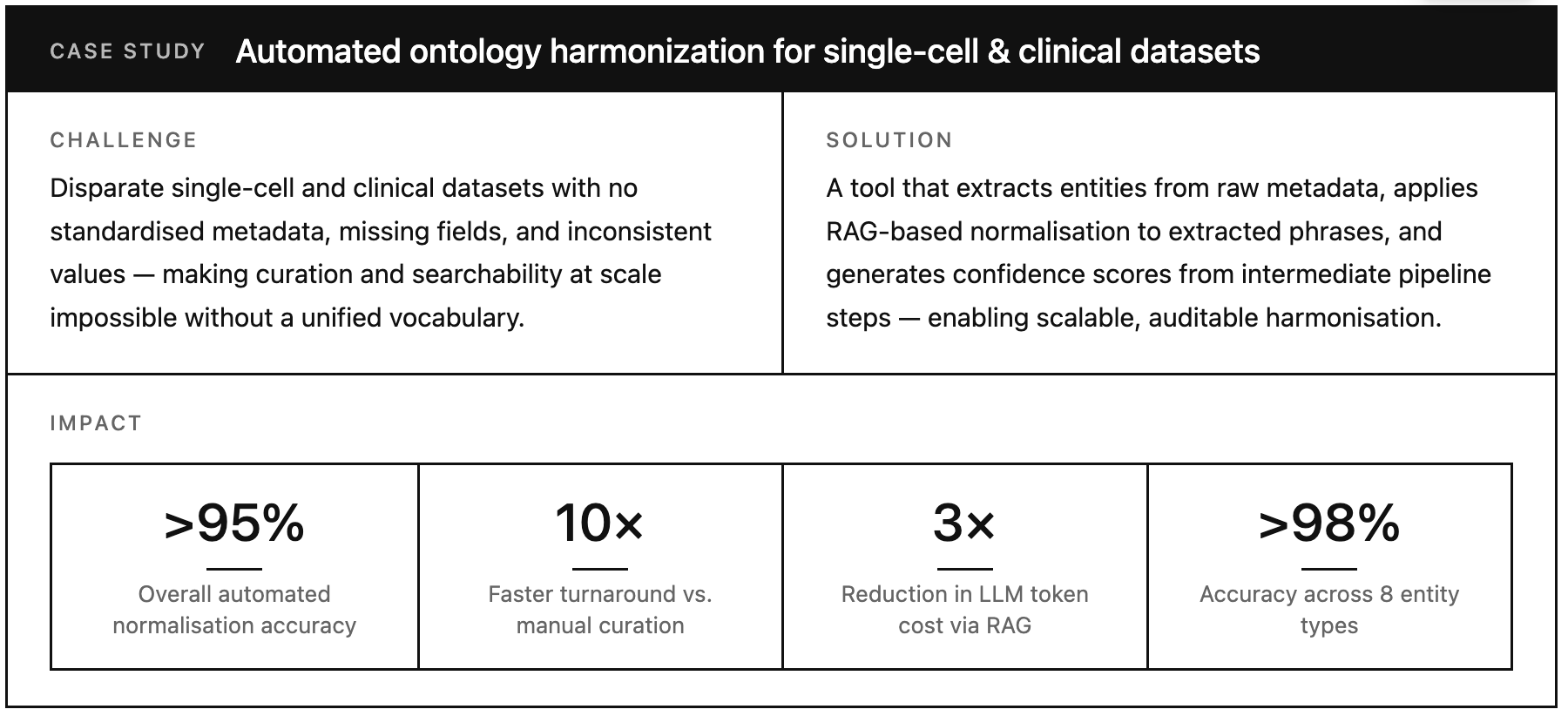
Insights Generation
Once cohorts and metadata have been assembled, researchers still face the challenge of interrogating large datasets and extracting relevant biological signals. Many analyses require programming expertise, custom scripts, or repeated interactions with data science teams.
The insights-generation agent enables researchers to explore structured datasets using natural language. The agent takes the user query and converts it into a logic statement which is then applied on a database.
Researchers can ask questions about cohort composition, disease stratification, treatment response, sequencing quality metrics, or molecular evidence without writing code. The system performs the required data transformations, generates visual outputs, and provides transparent explanations of the analytical steps involved.
Rapid Biological Insight Across Diverse Dataset Types
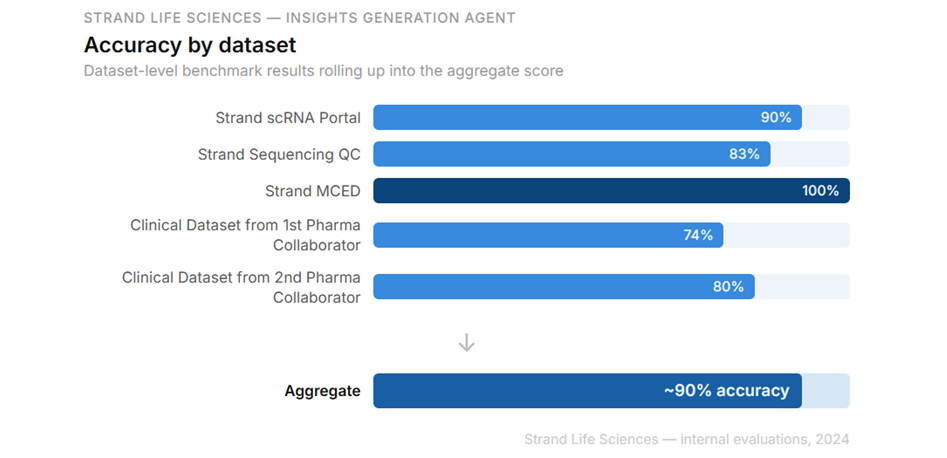
Across approximately 50 benchmark questions spanning textual and visual outputs, the framework achieved about 90% accuracy. Average response latency was 5.54 seconds, with query costs averaging around $0.20. Internal evaluations showed a sevenfold reduction in turnaround time for answering research questions, while project-specific assessments reported reductions of approximately 10–20 times compared with manual insight generation workflows.
The system has been evaluated across a diverse set of datasets, including curated inflammatory bowel disease metadata, sequencing quality-control records, multi-cancer early detection studies, clinicopathological datasets, and target-evidence repositories. This flexibility allows the framework to support both exploratory research and structured translational workflows.
Building a More Accessible Research Experience
The broader goal of the platform is to make complex biomedical datasets more accessible to scientists regardless of their computational background. By using agentic reasoning to help build and query structured, the system supports conversational exploration while maintaining traceability and database-grounded outputs.
The framework currently supports multiple model providers, including OpenAI, Gemini, Ollama, and OpenRouter, and can be deployed within local or on-premises environments to support data governance requirements. Researchers can build cohorts, query metadata, generate visualizations, retrieve supporting evidence, and explore large datasets through a unified interface.
As biomedical datasets continue to grow in scale and complexity, agentic AI provides a practical approach for reducing manual effort across discovery, curation, and analysis workflows. The result is a faster path from raw data to biological insight, allowing research teams to spend less time navigating data infrastructure and more time focusing on scientific questions.


Let's Connect
Let's Connect

download the case study.